Recently, I was recommended to look through Dynamo white paper, which is interesting and is helpful for Data Engineer to understand the concerns while designing a data store system or platform. So I plan to summarize some design ideas of these Store and some thoughts of mine.
Dynamo
Dynamo is a key-value NoSQL data store. Dynamo is developed for being used across hundreds of application of Amazon. As an eCommerce platform, large number of requests is common for these applications. Good user experience is vital for Amazon. Thus they build Dynamo around these concerns. Even, some other stores only focus on average of the latency. However, Dynamo takes care of the 99.9% percentile of latency to keep a good user experience. I would cover some impressive parts of the design here.
Always writable
Most of data stores are designed for read efficiency. But preventing providing a poor user experience, Dynamo goes against other data stores to achieve write efficiency, always writable. For example, with this feature, users can add and remove items from their shopping cart even with network and server failures. And then resolve the potential conflicts using some scheme like “last write wins” or keep both if resolving there is no causality of two writes in reading operation.
Partition Algorithm
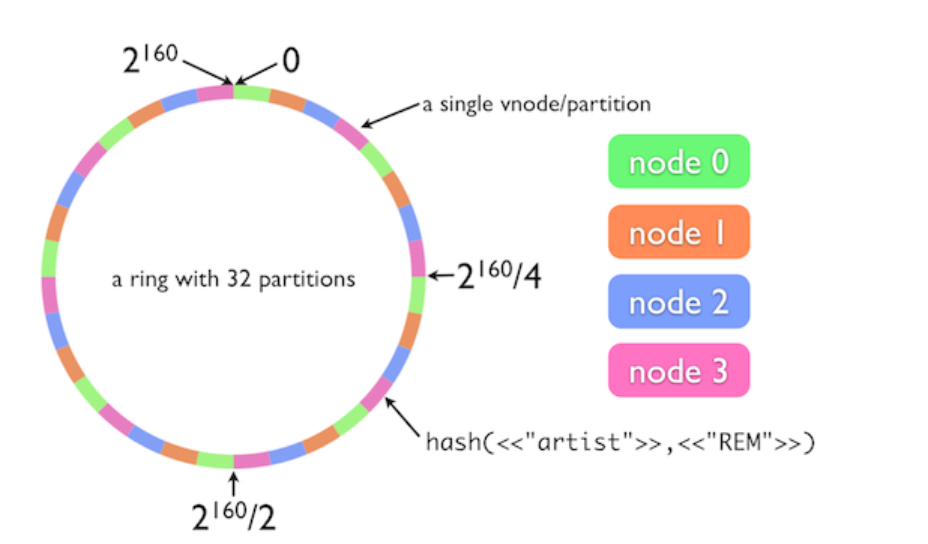
Dynamo uses consistent hashing to distribute the load across multiple hosts. The result of hash function is treated as a fixed circular or ring. Each node is assigned a random value to represent position on the ring. The key of the data item will be hashed to a position of the ring. Then find the first node with a position larger then the data item’s position. Now we find the start position and end position of the ring for the data item. The node in this range of the ring will be responsible for the data item. The advantage of this consistent hashing is that departure or arrival of a node only affects its immediate neighbors and other nodes remain unaffected.
Due to the random position assignment, data distribution will be unbalanced. Previously, a node will map to a single point in the ring. To prevent the unbalanced data distribution happening, nodes get assigned to multiple points in the ring. Another issue is that the basic algorithm doesn’t consider the performance of nodes. Atop the multiple points mapping solution, Dynamo use the concept of virtual nodes. A virtual node looks like a single node in the ring. But each node can be responsible for more than one virtual node. We can consider the data item assigned to a specific virtual node in the ring will be stored into multiple physical nodes responsible for that virtual node. When one node becomes available, the data item will be handled by the remaining nodes of that virtual nodes.
I found this picture to show the partition algorithm more intuitively.
Replication
Each data item is replicated at N hosts(pre-configured) to achieve high availability
and durability. Each node is assigned to a coordinate node(for READ and WRITE operation).
The job of the coordinate node is to ensure every data item that falls in
its range is stored locally and replicate to (N-1) nodes.
Data Versioning
Since the physical time is not a reliable source for maintain the version consistency of data store, Dynamo uses vector clock to capture the causality between different versions of the same object. Vector clock is a list of (node, counter) pairs. If there are two versions of an object, we can use vector clock to determine if these two versions is from parallel branches or have a causal ordering. For example, if the counters on the first object’s clock is less than or equal to all of the nodes in the second clock, it means the first is an ancestor of the second. Otherwise, two change will care considered to be in conflict. This logic is quite common in version control(git in my mind now).
Here is a small example of Dynamo data versioning from the white paper.
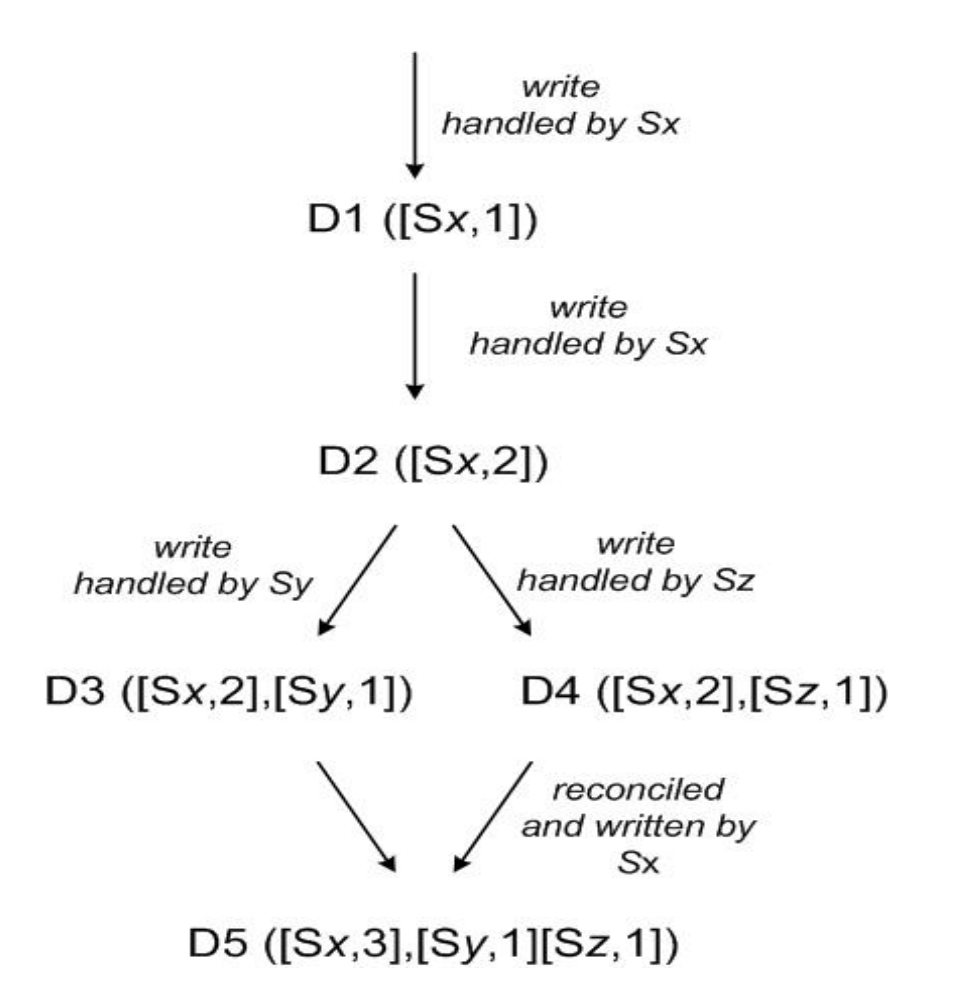
- Data Version 1: Written by Sx node
- Data Version 2: Written by Sx node (the counter increment)
- Data Version 3: Written by Sy node after Data Version 2
- Data Version 4: Written by Sz node after Data Version 2
- Data Version 5: Conflict Reconciled and written by Sx (the counter increment)
Execution of get() and put()
Dynamo is a key-value store. Thus the interface is simple, get() and put()(corresponding to
read and write respectively).
Read and write operation involves N healthy nodes to realize the consistency protocol similar to
other quorum systems. There are two key configurable values in this protocol. R is the minimum
number of nodes succeeding in read operation. W is the minimum number of nodes succeeding in
write operation.
For receiving a put() request for a key, the coordinator sends the new version to the N healthy
nodes. If at least W-1 nodes respond the the write is considered successful. For a get() request,
the coordinator will wait for R responses before returning the result to the client. During the
process, the coordinator will reconcile the divergent versions and write the reconciled version
back.
Takeaway
-
AWS S3 is a typical use of Dynamo. Considering every item name under a bucket is the key(which is consistent in S3 api), each item key corresponding to the data item we store in AWS S3.
-
Most of data systems have to concern following problems: load balancing, partition, replication, failure detection, failure recovery, overload handling, concurrency, job scheduling, request routing etc. These perspectives are also the parts I will pay attention to grind on in future.